Natureに掲載されたalphaGo_Zeroの記事を読む
教師有り学習としての棋譜学習をしなくても強化学習だけで無敵になったNatureに掲載されたAlphaGo_Zeroの記事を読んでみる。
上記のURLでpaperを押下するとNatureのサイトに行くが、大学とか特定の大企業では無料でPDFがdownloadできるメニューが現れる。現われない場合は大学か大企業の友人に頼むことになるが著作権違反になるかは分らない。
Alpha碁につてはこれもNatureで読み、かなり衝撃を受けたので下記の資料に纏めてみたことがある。
Alpha gor 2 from Masato Nakai
上記の資料の6ページにある様に従来のAlpha碁のNatureの記事では棋譜(教師)学習のSLと強化学習のRLのパイプラインで学習していた。

どの様にして棋譜学習が必要としない仕掛けになったか、Alpha碁がどの様に構造的に変化したか興味があった。
下図はアルファ碁のRLの推論展開で「早碁モデル」をつかったものだが、

Zeroの記事にある下図の推論過程は、上記の方法と比較して全く同じであるので、SL(棋譜学習)をすっ飛ばしてRLのみで済ましている様に見える。

しかし詳細に見ると下図で勝負の結果から着手確率
と場面価値
を一度に深層学習で求めている所が相違している。従来のAlpha碁では勝負結果
から価値
を逆算してDQNで着手を決定していた。
確かに着手確率とその裏付けの価値
とを同期をとって逆伝播して学習する方が精度を高めるのは間違いない。

従って損失関数は着手確率と価値
を一度に算出する次式となっている。
ここで
は次の着手の確率
は方策:学習過程を繰返しで形成された着手の分布
はパラメータの正則化項
またこの着手確率と価値
の損失関数を解くのに40層のResNetを使っている。
このResNetを使った方策と価値を統合することで、棋譜学習をせず強化学習のみで従来のAlpha碁より強いモデルを達成している様だ。
下図の従来の棋譜を使ったモデルと比較して、この記事の最終のコメントが衝撃的である。
「我々は人類が千年かかって作りあげた碁の知識をたった数日間で達成した!」
恐ろしい革新的な事態が次々起こってきそうである。

なお、アルファ碁のSLモデルの実装については下記参照
http://mabonki0725.hatenablog.com/entry/2017/03/29/090000
AlphaGo_Zeroの実装については下記が有名
深層学習で将来予測して最適行動する強化学習の論文を読む
深層学習で将来予測(Nステップ先)を予測して報酬を獲得する強化学習の論文を読む。
[1707.03497] Value Prediction Network
この論文はDQNの一手先のモデルを数手先を読むモデルに拡張したもので、かつ非常に洗練された構造をもつ強化学習である。
倉庫番問題等の数手先の将来予測を必要とする課題はDQNでは解けないものとして有名である。DeepMindでは下記の様なモデルを提案していたがモデルの考え方は非常に複雑で明瞭ではなかった。
DeepMindのI2Aモデルの倉庫番ゲームの論文を読む - mabonki0725の日記
この点本論文の将来予測モデルの構造がDQNのTree展開になっており、直感的て明瞭で発展の可能性がある。

ここでは観測される状態で
は行動オプションである
左の箱がコアとよばれこの中の近似関数は実際の報酬によってCNNやNNで学習される。

このコアは次のアルゴリズムで再帰的にTree構造で展開される。
この学習はDQNと同じTD法を多段階に拡張したものと見做せる。
損失関数は報酬と割引率
の
ノルムとなっている。
この論文で重要な知見として、このモデルは課題に依存するモデルベースではなく、DQNと同じモデルフリーとして汎用性があるとしている。
実験:
次の様な20回移動で最大の報酬(水色)を得る課題でDQNと比較している。下図ではDQNでは5個だが、本論のVPNでは6個報酬を獲得している。

下記にこの実装プログラムがある。
https://github.com/junhyukoh/value-prediction-network
回避機能をもつ逆強化学習の論文を読む
NIPS2017で発表されたAbbeel達の回避機能をもつ逆強化学習の下記の論文を読む。
「Inverse Reward Design」https://arxiv.org/abs/1711.02827
この論文は予想外の事象に衝き当った場合の報酬を如何に修正するかの話なので、報酬設定→行動経路→逆強化学習→報酬関数の修正なので逆強化学習の一種として考えられる。
予想外の事象に突き当った場合のロボットが、部分観察MDPの確信度で対処する行動決定とそっくりである。POMDPは確信度が低い場合には、近づいたり、スピードを落としたりして観察がよく出来る様に行動させる場合が多い。
この論文は、ロボットに目的の動作が出来る様に設定する報酬のデザインが誤ったり配慮が抜けてた場合でも、ロボットが当初の目的通りに動作できる様にするものである。
論文の下図の様な例では、デザイナーは報酬を目標=1 砂漠=0.1 草原=-1として、溶岩を思いつかなかった場合が示されている。
現実の世界(本論ではReal World)を相手にすると設計者の意図以外の事象に遭遇する場合が普通であって、この場合溶岩にはまって失敗する。

この論文の意図はDeepMindの様な理想とする環境での知的動作ではなく、Abbeel達は現実の世界の知的ロボットに関心があるので、この様なアイデアを考えたと思われる。
デザイナーが与えた報酬で訓練したロボットの経路を逆強化学習して、報酬関数の重みを以下で計算した場合でも、想定外の事象では重
みの信頼度を下げて、回避しょうとするのがこの論文のアイデアである。
ここで
は動作経路
は特徴量
重みの信頼度はエネルギー関数を採用してた次式の事後分布としている。
ここで
は現実世界に対応した真の重み
はMDP過程
は感応度(ハイパーパラメータ)
は特徴量の期待値
は分配関数
分配関数は算出すべき重み
が不明であるので一般には計算不能であるが、経路
を多くサンプリングして近似する場合が多い。
ここではランダムなサンプリング法(sample-Z)と最大エントフィ法で解いた(Maxent-Z)を使って上記の重み信頼度を計算している。
センサーが未知物体を感知した場合、一つの案として自己位置の認識に下図の様に特徴量に多次元のガウスう分布を使って重みの信頼度を計算している。

想定外の場合では特徴量が変化するので、重み
の信頼度が低下し、低い重みで報酬
を計算すると、報酬
が低くなるので、回避することができる。
実験では分配関数をMaxEnt-ZやSample-Zを用いて重みの信頼度を計算した方が、この手当てをしない場合 Proxyより、遥かに溶岩を回避できている。
右図は未知物体では重みの信頼度の事後分布で計算した実験
左図は未知物体に統計モデルを使用した実験

Negative Side Effects センサーの想定外検知
Reward Hacking センサー情報の相互矛盾検知
Raw Ovservation ガウス分布を使って判定する
Classifyer Feature 識別器を使って判定する
FIRLの論文を読むが難しい
ベイズによる逆強化学習が、杉山先生の密度比による逆強化学習と同じ手法になったので、残る有名な手法はFIRL(Feature Construction IRL)のみになった。
この手法は下記のAbbeel率いるBarkleyチームのLevineによる論文がある。
https://homes.cs.washington.edu/~zoran/firl.pdf
この手法はこれまでの報酬を固定の特徴量の近似関数で表す手法と全く異なっていて、特徴量を回帰木で分解して有意な特徴量を選択しながら、2次計画法で最適な報酬関数を求める方法となっている。

ここで
は熟練者の行動データ
は回帰木で選択した特徴量
は改善対象の報酬関数
は同じ状態をもつグループを繋ぐ正則化項
拘束条件では熟練者の行動範囲であれば、正しい価値関数
が計算され、それを逸脱すると、劣化した価値関数
が計算される。逸脱した行動
は観測できないので
の罰則を与えている。
回帰木は、次式で定義され、枝に含まれる状態を報酬の寄与で分割して、最適な回帰木は上記の2次計画法で算出している。
ここで
は木の枝でこのノードに含まれる状態
で報酬に寄与しない側
は木の枝でこのノードに含まれる状態
で報酬に寄与する側
は状態
が報酬に寄与するか判断する関数
は状態
がこのノードに含まれるかの指標
と
はさらに回帰木を生成していくが、経験的に浅い分岐でよいとしている。
この論文は式記号も難しく、本当に妥当な回帰木が得られるか判断が付かない。詳しいロジックを追求するには下記のMatlabのサイトがある。
逆強化学習に詳しい千葉大の荒井研究室ではこのFIRLを昨年稼動して発表している。しかしFIRLの優位性を示せてなく記述も簡単すぎて詳しい事がわからない。
ガウス過程による逆強化学習を実装(python)してみる
先日下記の論文について自分の理解を述べたが、文献に沿ったプログラムがあったので、これを自分なりに修正して稼動してみると、完全に自分の理解が誤っていたことが判明した。もし以前の記述を読んだ方がいれば大変申し訳なく、下記にて修正させて頂きます。
Nonlinear Inverse Reinforcement Learning with Gaussian Processes
(1)ロジックの説明
プログラムによって理解したロジックです。
この手法のプログラムを読むと、ガウス過程の逆強化学習は以下の手順で行っています。
① 局面を表す特徴量を選定します。
②熟練者の操作過程の特徴量を記録します。
⑥の尤度(IRL term)が最大になるまで③から⑥を繰返します。
③特徴量の記録から、ガウスカーネルのパラメータ
を最大尤度(GP probability) で計算します
④次式に従って特徴量と観測された報酬
でカーネル過程回帰します
⑤擬似報酬の事後分布で真の報酬
を逆算します
この事後分布(GP posterior)は尤度分布と事前分布ともガウス分布なので
理論解で計算できます
⑥真の報酬よりBellman方程式を解いてこの尤度(IRL term)を計算します。
根拠のロジックは次式の式になります。

ここで
は熟練者のデータ
は特徴量
は観測された報酬
は真の報酬
IRL termはBellman方程式の解
GP posterior はガウス分布の事後分布
GP probabilityはガウス過程回帰
(2) 実験課題
5×5のセルにマーク1と2がある。各セルにエージェントは上下左右に移動する
マーク1からの距離が3以内でかつマーク2からの距離が2以内のセルに居るなら報酬を得る
マーク1から3超かマーク1に居るなら罰則がある。
この規則に従うと以下の報酬になる。

(3) 実装した結果
熟練者のデータは上記(2)のルールに従って移動して、その100経路のログを記録している。
この行動記録から上記(1)のロジックで報酬を算出している。
但し、ARD(Auto Relevant Decision 自動関連決定)のガウスカーネルを使用した。
ガウス過程による逆強化学習の結果(右)は真の報酬に近い値となっている。

参照したプログラムが探しだせなくなったので、自分が修正したプログラムを示します。
逆強化学習の課題にPlen2を使う
学校の研究でPlen2を使った逆強化学習を企画しているが、初めてPlen2を使ってみた。
このToyロボットはサーボモータでの稼動点が20点あり、ここに信号を送って逆強化学習の実証実験をする。
このPlen2はArdinoが20個のモータを制御する仕掛けで現在8万円弱とまだ高価である。
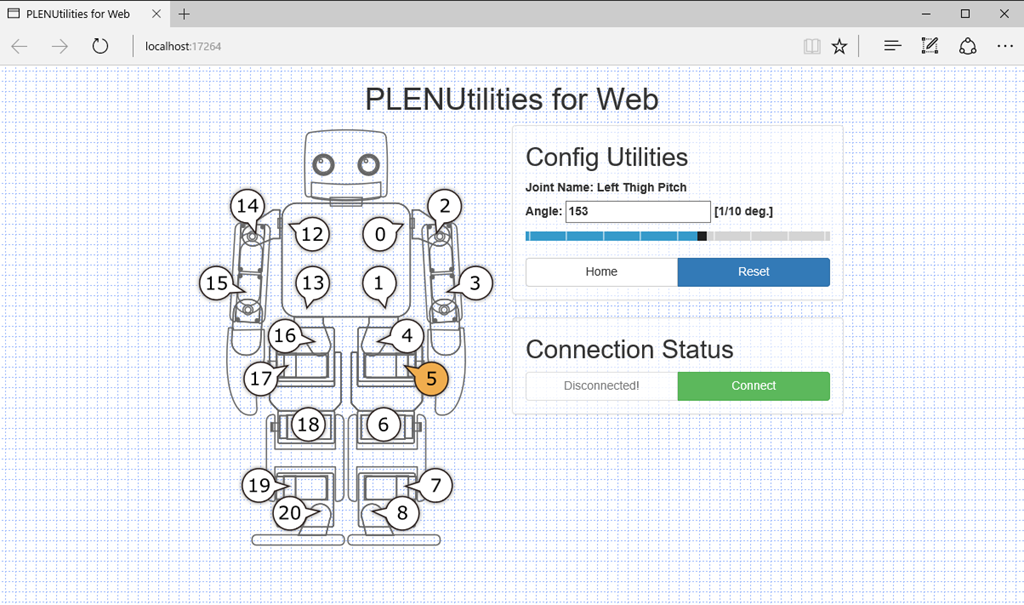
Plen2はPC上のWebを使ったコントロール画面で動作を定義する。
PC上のWebサーバがを通じてPlen2と通信する仕組み。
まずは、下のURLに従ってFirmWareをインストールする。
http://plen.jp/playground/wiki/tutorials/plen2/firmware
動作に関しては、下図のモーション・編集はExcelのマクロ記憶の様に保存して、これを呼び出す仕掛けだがこの動作にエラーが出ている。

ガウス過程による逆強化学習の論文を読む
最大エントロフィの逆強化学習の性能はベイズより優れていることは実装してみて判明したが、下記の論文によるとガウス過程(Gaussian Process)を使った逆強化学習が傑出してよい性能を出している。
この論文の高速道路の実験例をみるとパトカーやパトバイクに近い所は人間がスピード抑制をしている事が観測されている。

左上が人間のスピード抑制データ(濃い色)で、GPIRL(ガウス過程逆強化学習)が殆ど等しいことが示されている。ここでの比較先は
MaxEntIRL(最大エントリフィIRL)
FIRL(Feature Construction IRL)
この手法のプログラムを読むと、ガウス過程の逆強化学習は以下の手順で行っています。
① 局面を表す特徴量を選定します。
②熟練者の操作過程の特徴量を記録します。
⑥の尤度(IRL term)が最大になるまで③から⑥を繰返します。
③特徴量の記録から、ガウスカーネルのパラメータ
を最大尤度(GP probability) で計算します
このは特徴量
の正則化項のパラメータです
は乱数を振って上式が最大(最尤度)となる値を採用しています。
④式(3)に従って特徴量と観測された報酬
でカーネル過程回帰します

これはカーネルを分散とする対数分布ですが、最後に
が追加されています。
⑤擬似報酬の事後分布で真の報酬
を逆算します
この事後分布(GP posterior)は尤度分布と事前分布ともガウス分布なので
理論解で計算できます
報酬と特徴量
のカーネル
を使っています。問題は報酬
の算出にこれが未定なのに使っています。よってこの式は仮置きの報酬
を使って、SGDの繰返しで精緻化する方針としています。
⑥式(2)のは仮置きの報酬
よりBellman方程式を解いてこの式(2)尤度(IRL term)を計算します。
ここで
は熟練者のデータ
は特徴量
はガウス過程
は報酬
は
の正則化項
IRL termはBellman方程式の解
GP posterior はガウス分布の事後分布
GP probabilityはガウス過程回帰
⑦仮置きの報酬をSGDで精緻化するため、本論文ではL-BFGSを使ったと記述があります。この微分式については下記のSupprementに詳細に記述され、Python版ではこの通り実装されています。
Nonlinear Inverse Reinforcement Learning with Gaussian Processes 
ここで諸値は以下で与えられる
エネルギーベースの逆強化学習
ここで
ここでなので
は
実験課題
黄色の位置から3距離までと赤の位置から2距離の場合に居続けると報酬が加算される(左下の赤い範囲)。コマを上下左右に移動して報酬の多寡で強化学習を行った軌跡をデータとして保存する。
強化学習で学習した軌跡でPythonによるガウス過程を使った逆強化学習の結果が右図。一応左図の真の結果に近く細かい報酬が得られている。