FIRLの論文を読むが難しい
ベイズによる逆強化学習が、杉山先生の密度比による逆強化学習と同じ手法になったので、残る有名な手法はFIRL(Feature Construction IRL)のみになった。
この手法は下記のAbbeel率いるBarkleyチームのLevineによる論文がある。
https://homes.cs.washington.edu/~zoran/firl.pdf
この手法はこれまでの報酬を固定の特徴量の近似関数で表す手法と全く異なっていて、特徴量を回帰木で分解して有意な特徴量を選択しながら、2次計画法で最適な報酬関数を求める方法となっている。

ここで
は熟練者の行動データ
は回帰木で選択した特徴量
は改善対象の報酬関数
は同じ状態をもつグループを繋ぐ正則化項
拘束条件では熟練者の行動範囲であれば、正しい価値関数
が計算され、それを逸脱すると、劣化した価値関数
が計算される。逸脱した行動
は観測できないので
の罰則を与えている。
回帰木は、次式で定義され、枝に含まれる状態を報酬の寄与で分割して、最適な回帰木は上記の2次計画法で算出している。
ここで
は木の枝でこのノードに含まれる状態
で報酬に寄与しない側
は木の枝でこのノードに含まれる状態
で報酬に寄与する側
は状態
が報酬に寄与するか判断する関数
は状態
がこのノードに含まれるかの指標
と
はさらに回帰木を生成していくが、経験的に浅い分岐でよいとしている。
この論文は式記号も難しく、本当に妥当な回帰木が得られるか判断が付かない。詳しいロジックを追求するには下記のMatlabのサイトがある。
逆強化学習に詳しい千葉大の荒井研究室ではこのFIRLを昨年稼動して発表している。しかしFIRLの優位性を示せてなく記述も簡単すぎて詳しい事がわからない。
ガウス過程による逆強化学習を実装(python)してみる
先日下記の論文について自分の理解を述べたが、文献に沿ったプログラムがあったので、これを自分なりに修正して稼動してみると、完全に自分の理解が誤っていたことが判明した。もし以前の記述を読んだ方がいれば大変申し訳なく、下記にて修正させて頂きます。
Nonlinear Inverse Reinforcement Learning with Gaussian Processes
(1)ロジックの説明
プログラムによって理解したロジックです。
この手法のプログラムを読むと、ガウス過程の逆強化学習は以下の手順で行っています。
① 局面を表す特徴量を選定します。
②熟練者の操作過程の特徴量を記録します。
⑥の尤度(IRL term)が最大になるまで③から⑥を繰返します。
③特徴量の記録から、ガウスカーネルのパラメータ
を最大尤度(GP probability) で計算します
④次式に従って特徴量と観測された報酬
でカーネル過程回帰します
⑤擬似報酬の事後分布で真の報酬
を逆算します
この事後分布(GP posterior)は尤度分布と事前分布ともガウス分布なので
理論解で計算できます
⑥真の報酬よりBellman方程式を解いてこの尤度(IRL term)を計算します。
根拠のロジックは次式の式になります。

ここで
は熟練者のデータ
は特徴量
は観測された報酬
は真の報酬
IRL termはBellman方程式の解
GP posterior はガウス分布の事後分布
GP probabilityはガウス過程回帰
(2) 実験課題
5×5のセルにマーク1と2がある。各セルにエージェントは上下左右に移動する
マーク1からの距離が3以内でかつマーク2からの距離が2以内のセルに居るなら報酬を得る
マーク1から3超かマーク1に居るなら罰則がある。
この規則に従うと以下の報酬になる。

(3) 実装した結果
熟練者のデータは上記(2)のルールに従って移動して、その100経路のログを記録している。
この行動記録から上記(1)のロジックで報酬を算出している。
但し、ARD(Auto Relevant Decision 自動関連決定)のガウスカーネルを使用した。
ガウス過程による逆強化学習の結果(右)は真の報酬に近い値となっている。

参照したプログラムが探しだせなくなったので、自分が修正したプログラムを示します。
逆強化学習の課題にPlen2を使う
学校の研究でPlen2を使った逆強化学習を企画しているが、初めてPlen2を使ってみた。
このToyロボットはサーボモータでの稼動点が20点あり、ここに信号を送って逆強化学習の実証実験をする。
このPlen2はArdinoが20個のモータを制御する仕掛けで現在8万円弱とまだ高価である。
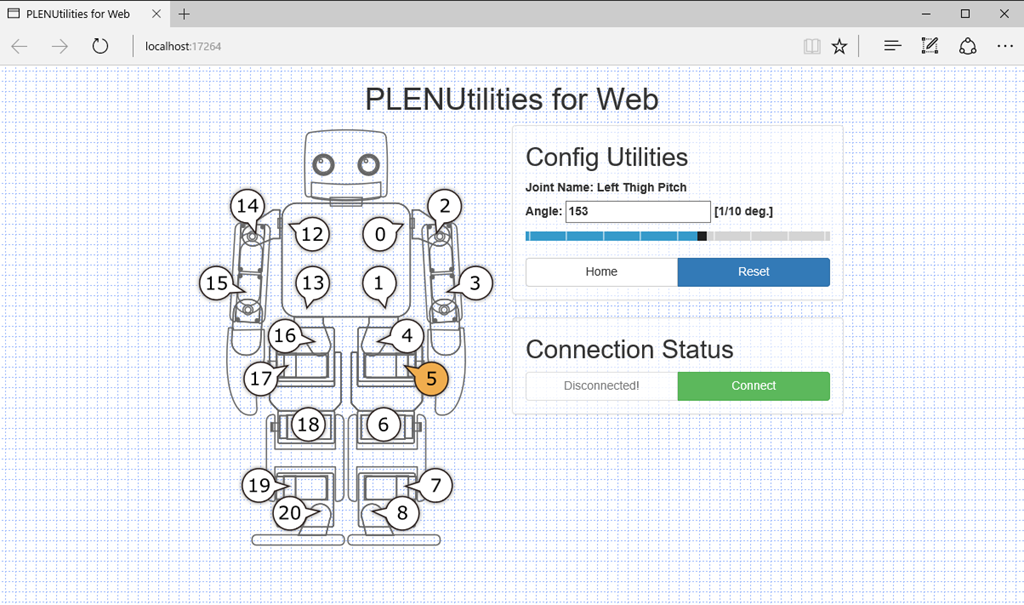
Plen2はPC上のWebを使ったコントロール画面で動作を定義する。
PC上のWebサーバがを通じてPlen2と通信する仕組み。
まずは、下のURLに従ってFirmWareをインストールする。
http://plen.jp/playground/wiki/tutorials/plen2/firmware
動作に関しては、下図のモーション・編集はExcelのマクロ記憶の様に保存して、これを呼び出す仕掛けだがこの動作にエラーが出ている。

ガウス過程による逆強化学習の論文を読む
最大エントロフィの逆強化学習の性能はベイズより優れていることは実装してみて判明したが、下記の論文によるとガウス過程(Gaussian Process)を使った逆強化学習が傑出してよい性能を出している。
この論文の高速道路の実験例をみるとパトカーやパトバイクに近い所は人間がスピード抑制をしている事が観測されている。

左上が人間のスピード抑制データ(濃い色)で、GPIRL(ガウス過程逆強化学習)が殆ど等しいことが示されている。ここでの比較先は
MaxEntIRL(最大エントリフィIRL)
FIRL(Feature Construction IRL)
この手法のプログラムを読むと、ガウス過程の逆強化学習は以下の手順で行っています。
① 局面を表す特徴量を選定します。
②熟練者の操作過程の特徴量を記録します。
⑥の尤度(IRL term)が最大になるまで③から⑥を繰返します。
③特徴量の記録から、ガウスカーネルのパラメータ
を最大尤度(GP probability) で計算します
このは特徴量
の正則化項のパラメータです
は乱数を振って上式が最大(最尤度)となる値を採用しています。
④式(3)に従って特徴量と観測された報酬
でカーネル過程回帰します

これはカーネルを分散とする対数分布ですが、最後に
が追加されています。
⑤擬似報酬の事後分布で真の報酬
を逆算します
この事後分布(GP posterior)は尤度分布と事前分布ともガウス分布なので
理論解で計算できます
報酬と特徴量
のカーネル
を使っています。問題は報酬
の算出にこれが未定なのに使っています。よってこの式は仮置きの報酬
を使って、SGDの繰返しで精緻化する方針としています。
⑥式(2)のは仮置きの報酬
よりBellman方程式を解いてこの式(2)尤度(IRL term)を計算します。
ここで
は熟練者のデータ
は特徴量
はガウス過程
は報酬
は
の正則化項
IRL termはBellman方程式の解
GP posterior はガウス分布の事後分布
GP probabilityはガウス過程回帰
⑦仮置きの報酬をSGDで精緻化するため、本論文ではL-BFGSを使ったと記述があります。この微分式については下記のSupprementに詳細に記述され、Python版ではこの通り実装されています。
Nonlinear Inverse Reinforcement Learning with Gaussian Processes 
ここで諸値は以下で与えられる
エネルギーベースの逆強化学習
ここで
ここでなので
は
実験課題
黄色の位置から3距離までと赤の位置から2距離の場合に居続けると報酬が加算される(左下の赤い範囲)。コマを上下左右に移動して報酬の多寡で強化学習を行った軌跡をデータとして保存する。
強化学習で学習した軌跡でPythonによるガウス過程を使った逆強化学習の結果が右図。一応左図の真の結果に近く細かい報酬が得られている。
ベイズによる逆強化学習をC言語で実装してみた
本郷で行われた強化学習アーキテクト(2018/01/16)は千葉大学Dの石川翔太さんのベイズによる逆強化学習であった。
https://www.slideshare.net/ShotaIshikawa2/ss-86214928
最大エントロフィ法の逆強化学習を実装して見て納得できなかった事は、熟練者の方策変更を反映できない事であった。
その点ベイズでは熟練者のデータを分類して、その方策の移動を隠れ変数として反映できる可能性がある。
以下の文献に従って簡単な、ベイズによる強化学習を実装してみた。
https://www.aaai.org/Papers/IJCAI/2007/IJCAI07-416.pdf
プログラム(python) としては下記のGitHubを参照しました。
https://github.com/erensezener/aima-based-irl
熟練者の選択確率をとすると報酬
はベイズより次式の事後分布で算出する事ができる。
ここで
:局面
:行動
は観測された熟練者の遷移経路
:熟練者の報酬の事前確率
:分配関数
は行動価値関数 Bellman方程式で解く
隠れ変数Rを変動させて事後分布を最大とするMAP(Maximum Posterior)をすればよい
ベイズモデルの有意性は上記の様に定式化が明確で理解し易いことにあるが、一般に事後分布は尤度関数が共役事前分布でないと理論的に解けず、MCMCによる繰返し計算が必要になる。
以下の手順で計算する。
①報酬の事前分布は一様分布とする
②MCMCを使って最適を探査する
簡単にいうと一様分布の報酬をランダムに変えて生成した熟練者の事後分布が高くなるなら、これを採用する
③生成する尤度分布は仮定された
よりBellaman方程式を解いて価値行動関数
に指数比例とする(ボルツマン分布の仮定)
は熟練者の局面
での最適行動
この実装では熟練者の経路から局面での最頻度行動としている。
上記のpythonの例だと熟練者の事前報酬を仮定して採用している。
④ 乱数で生成された報酬での熟練者の事後分布が、前に計算された事後分布より高くなれば、この仮定された報酬
を選択する。
実験課題
課題は最大エントロフィ逆強化学習と同じ問題とする。
赤がゴール。熟練者データはOpen-AIで解いた100通りの経路とする。

実験結果
ゴールに近い所が報酬が高く、遠い所が低く計算できている。
最大エントロフィ逆強化学習よりは粗い結果となっている。これは熟練者の最適方策を単に経路データから最頻度行動を採用しているためと考えられる。

UC.Berklayの協業強化学習の論文を読む
複数の自律体での強化学習は敵対的なモデルが一般的ですが、この論文は複数の自律体が協同で問題を達成するモデルの論文で、DeepMindと双璧を成すUC.Berklayの発表です。
https://people.eecs.berkeley.edu/~russell/papers/icml17ws-cirl.
「Efficent Cooperative Inverse Reinforcement Learning」
問題設定はChefWorldと云い人間とロボットが協同で料理の材料を用意して、なるべく多くの料理を作るゲームです。
このモデルはAdaptive-CIRLとして以下の実験結果が報告されています。横軸は材料数、縦軸は成功した料理数です。材料数が増えた場合、論文のモデルが傑出して高い精度を出しています。 
この問題はロボットは人間の意図や好みを推測して材料を提供する必要があるので、ロボット側から見ると人間の好みを観察して合わせる必要があります。それでCIRL(Cooperative Inverse Reinforcement)として人間の行動をデータとする逆強化学習としてモデル化できますが、人間の好みが見えないPOMDP(部分観察マルコフ決定過程)として捉える事ができます。
POMDPでは一般に観察データから状況
を推察する確信度
を導入します。一般には観察データから正解の状況
で回帰で求めらることが多いです。
この論文では価値関数はBellman方程式に類推確率
を考慮して以下に改変して計算しています。
ここで
:観察データ
は観察zでの状況s'の価値
大きな問題は協業なので、人間の意図に沿わない材料をロボットが用意した場合でも料理にする必要があります。
この論文では、人間の類推確率を以下で更新しています。
ここで
T:推移確率
状態は(観察
,パラメータ
)で定義
は人間の行動
はロボットの行動
複数の自律体の強化学習は、逆強化学習よりも互いの意図を確信度で代替するPOMDPでも実現できること示した意義があると考えられます。
UC.Berkeleyの敵対的逆強化学習の論文を読む
Abbeel率いるUC.Berkeleyのロボット学者達が昨年初「GANとIRL」は同義だとする画期的な論文を示しましたが、この一派がまたこの論文に述べられたGAN-GCLを発展させたGANによるIRLの論文(Adversarial Inverse Reinforcement Learning:AIRL)を発表しました。
[1710.11248] Learning Robust Rewards with Adversarial Inverse Reinforcement Learning
GAN-GCL(Genarative Adversarial Network-Guided Cost Learning)では経路を使った識別関数でしたが、この手法は安定しないため、局面()での識別関数に変更して性能を向上させました。
この識別関数はGANの定義通りで以下となります。
ここで
は熟練者の局面
行動
での選択率を与える擬似関数(
が特徴量)
はIRLで生成された擬似方策
このモデルは熟練者の選択とIRLで生成された擬似方策を識別関数で識別し、これを改善することによって熟練者の選択・擬似関数を改善します。
論文では以下の①~③を繰返す敵対的アルゴリズムとなっていて、繰返し毎に熟練者と擬似IRLの生成結果を近似していきます。
①局面 行動
でのデータが熟練者によるものか、IRLで生成されたデータか判断し識別関数
を改善します。
②報酬は上記の識別関数を次式に投入すると、IRLの公式となるので計算できます。
ここでは報酬擬似関数と価値擬似関数
に分離して近似解を解いています。
③得られた報酬より擬似方策
を計算します。
実験では以下の2つの訓練時と試験時では異なる強化学習の精度を比較しています。

Pointmass-Maze Ant-Disabled
左図は訓練時は緑→青へ、試験時は青→緑へ移動する実験
右図は訓練時は4本同じ足で前進、試験時は前足が短くしています。
比較先としてTRPOによる経路を真値としています。

ここで State-OnlyのYesは識別関数が(s,a)で判定しており、Noは経路()での識別判定です。特にAnt-DisabledではAIRLでないと全く試験時には前に動作しないと述べています。
流石にGANとIRLが同等である事を示したチームのモデルであるだけに敵対的なIRLモデルとなっています。
なお、GANとIRLが同等である説明資料を以下に添付します。
Irs gan doc from Masato Nakai